Security Pillar
After the initial operational excellence design discussions, implementing a strong security foundation is next. After a workload has been deployed, the management of workload security is paramount. Organizations must design security into their cloud solution architectures to protect the workload and ensure its survival from attacks and catastrophic events.
If your online store or customer portal is knocked offline by hackers or corrupted with false or damaging information, your organization’s reputation and customers could be maligned. What if customers’ financial, medical, or other personal informa-tion is leaked from your systems? Organizations must design, deploy, test, monitor, and continuously improve security controls from the beginning. Security requires planning, effort, and expense, as nothing is more valuable than your customers and your ability to securely deliver applications and services meeting their needs. Strategies need to be employed to help achieve the security, privacy, and compliance required by each application and its associated components. These strategies are discussed next.
Defense in Depth
Defense in depth can be divided into three areas: physical controls, technical con-trols, and administrative controls. AWS as the cloud provider is responsible for secu-rity of the cloud; therefore, AWS is responsible for securing the physical resources using a variety of methods and controls. AWS also is responsible for providing technical and administrative controls for the cloud services its customers are using, so that they may secure and protect their application stacks and resources that are hosted in the cloud.
Each component of your application stack should have relevant security controls enabled to limit access. For example, consider a two-tier application consisting of web servers and an associated relational database. Both the web and database servers should be hosted on private subnets with no direct access to the Internet. Access to the Internet for updates and licensing should be controlled by using network address translation (NAT) services that allow indirect access from private subnets to the Internet for server updates. For public-facing applications, the load balancer should be placed on a public subnet accepting and directing requests to the web servers hosted on private subnets. Firewalls should be in place at each tier: To protect incoming traffic from Internet attacks, web application firewalls filter out undesir-able traffic (see Figure 2-2). Each web and database server should be also protected by firewalls that allow only the required traffic through. Each subnet should be secured with network access controls that allow the required traffic and deny all other requests. Encryption should be deployed for both data in transit and data at rest.

Figure 2-2 Defense in Depth Using AWS Services
Other security strategies include implementing the principle of least privilege using identity and authorization controls. AWS Identity and Access Management (IAM) allows customers to create permission policies for users, groups, and roles for cloud administrators, cloud services, and end users that access cloud resources from their mobile devices (see Figure 2-3).

Figure 2-3 Identity and Access Management Security Controls
There are many security services you can enable in the cloud, allowing organizations to reap the benefits. For example, Amazon GuardDuty provides intelligent threat detection using machine learning to provide continuous monitoring of network traffic, DNS queries, and API calls, and protect access to RDS databases and Kubernetes deployments.
Reliability Pillar
Reliability is the most important requirement; without reliability, end users will eventually stop using the application. Each workload should be designed to mini-mize failure, keeping in mind there are many components in each application stack to consider. Over the past decade, many best practices have been published as to how to best deploy and manage workloads and associated AWS cloud services with a high degree of reliability.
Organizations must define the required level of reliability for each workload deployed in the AWS cloud. Cloud reliability is commonly defined as cloud ser-vice availability. Before the cloud, a service-level agreement (SLA) was an explicit contract with the provider that included consequences for missing the provider’s service-level objectives. AWS SLAs indicate that they will do their best to keep their infrastructure and managed services up and available most of the time. Each AWS cloud service typically has a defined SLA that defines an operational uptime goal which AWS attempts to meet, and usually exceeds (see Figure 2-4). If failures occur, and they do occur from time to time, and you can prove that a workload was down because of AWS’s failures, AWS will provide you with a credit on your bill. AWS SLAs can be found here: https://aws.amazon.com/legal/service-level-agreements/.
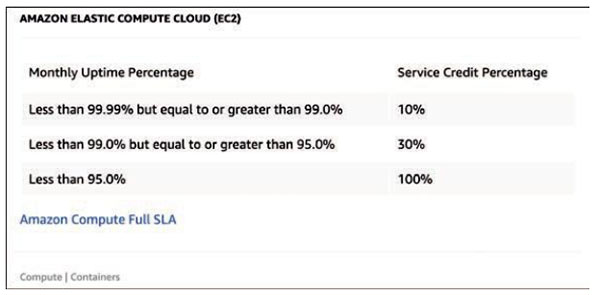
Figure 2-4 AWS Service-Level Agreements
SLA numbers that define cloud service availability look better than they really are. For example, demanding a desired application availability of 99.99% is design-ing for the potential unavailability over a calendar year of roughly 52 minutes of downtime. Because potential downtime does not include scheduled maintenance, when is this 52 minutes of downtime going to occur? That is the big question to which there is no guaranteed answer. If your workload is streaming video delivery, 99.99% is the recommended availability target to shoot for. If your workload pro-cesses ATM transactions, a maximum unavailability of 5 minutes per year, or five nines (99.999%), is the recommended availability target to shoot for. For an online software as a service (SaaS) application involving point-of-sale transactions, the recommendation is 99.95%, or roughly 4 hours and 22 minutes of downtime per year. Other considerations when calculating workload availability include workload dependencies and availability with redundant components.
- Workload dependencies: On-premises workloads will have hard dependen-cies on other locally installed services; for example, an associated database. Operating in the AWS cloud, if a dependent database fails, a backup or standby database service can be available for automatic failover. In the AWS cloud, workloads can more easily be designed with a reliance on what are defined
as soft dependencies. With each AWS region containing multiple availability zones, web and application servers deployed across multiple availability zones fronted by a load balancer provide a highly available design. Databases are also deployed across at least two availability zones, and the primary and secondary database servers are kept up to date with synchronous replication.
- Availability using redundant components: Designing with independent and redundant cloud services, availability can be calculated by subtracting the availability of the independent cloud services utilized by your workload from 100%. Operating a workload across two availability zones, each independent availability zone has a defined availability of 99.95%. Multiplied together and subtracted from 100%, availability is six nines, or 99.9999% (see Figure 2-5).
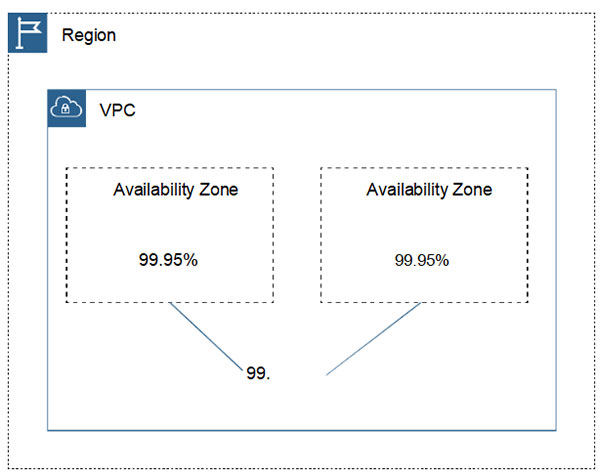
Figure 2-5 Multi-AZ Service-Level Agreements
NOTE Applications that are designed for higher levels of availability will also have increased costs. Workloads designed with high availability will have multiple web, application, and database instances across multiple availability zones.