Caching Data with CDNs
If Julian is the first user in the last 24 hours to load any of the requested files, the Winnipeg CDN POP won’t find the files in its temporary cache. The POP would then relay a web request to the website origin address hosted in the cloud region hundreds of miles away.
When another customer in the Winnipeg region, Jan, visits the web portal site, her browser resolves the site name to the Winnipeg CDN POP just as Julian’s had done recently. For each file that is still cached locally, the POP will send back an imme-diate local response; without consulting the web server hundreds of miles away, Jan gets a super-fast experience. And the hundreds, thousands, or millions of other customers who visit the Terra Firma web portal can get this performance benefit as well. AWS CloudFront, AWS’s CDN, provides hundreds of POPs around the world (see Figure 2-9). Wherever users are located, there is likely a POP locally or within the same geographical area. Users close to the actual website AWS cloud region can also be serviced by a POP in that cloud region. People far away will get the same benefits once another end user in their area visits the Terra Firma website, which will automatically populate their local POP’s cache.
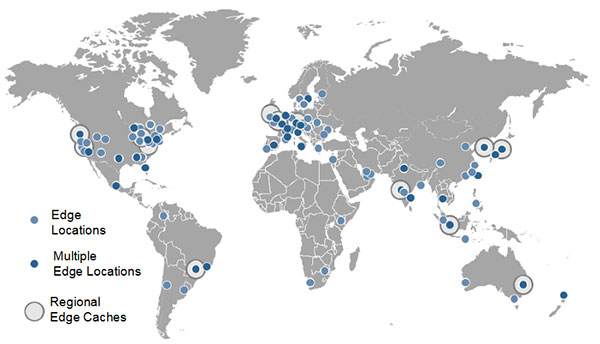
Figure 2-9 Amazon CloudWatch Edge Locations
NOTE CDN caching techniques must be explicitly programmed and configured in your application code and in the Amazon CloudWatch distribution. Deploying a CDN is designed to improve performance and alleviate the load on the origin services, as in our example of a web portal.
Data Replication
Although CloudFront focuses on performance, a CDN provides substantial security, reliability, cost, and operations benefits. But what if your workload design also stores persistent replica copies of your data, resulting in multiple copies of data? Let’s look at the benefits of cloud storage and replicated data records.
The applications, cloud services, and data records that make up your workload solu-tions must be reliable. A single database or website is a single point of failure that could bring down the entire workload. Organizations don’t want their business to fail, so they need to architect and engineer systems to avoid any single points of fail-ure. To improve reliability in cloud solutions architectures, customers need to make choices about redundancy, replication, scaling, and failover.
AWS provides multiple replicas of data records that are stored in the cloud. Three copies is a common default, with options for greater or lesser redundancy depending on the storage service chosen. There are additional options for expanding or reduc-ing additional data replication. Storage and replication are not free; customers must pay for the used storage infrastructure consumed per month. Network transfer costs are billed relative to the rate of change and duplicate copies are billed based on the stored capacity used. Always check with AWS for up-to-date and region-specific pricing of storage, databases, and replication for these services. Deploy the required configurations at AWS to enable the desired redundancy for every database, data lake, and storage requirement:
- Replicate within an availability zone if necessary
- Replicate between availability zones within your primary AWS region
- Replicate between your chosen primary AWS cloud region and one or more secondary regions
Operating in the AWS cloud requires security and replication at all levels. Custom-ers should also consider deploying compute containers, virtual machine instances, or clusters of either to multiple availability zones and across regions to meet their needs.
Load Balancing Within and Between Regions
When we have more than one replica of an EC2 instance or containerized applica-tion, we can load balance requests to any one of those replicas, thereby balancing the load across the replicas (see Figure 2-10). Read operations, queries, database select statements, and many compute requests can be load balanced, as can writes to multi-master database systems.
- Network load balancers use Internet protocol addresses (IPv4 or IPv6), with a choice of TCP, UDP, or both on top of IP and with port numbers to identify the application or service running. Rules stating how to block or relay network traffic matching the source and target IP address, protocol, and port patterns dictate the load-balancing process.
- Application load balancers indicate that HTTP or HTTPS traffic is being load balanced, with balancing rules based on web URLs with rule choices of HTTP or HTTPS, domain name, folder and file name, web path, and query strings.
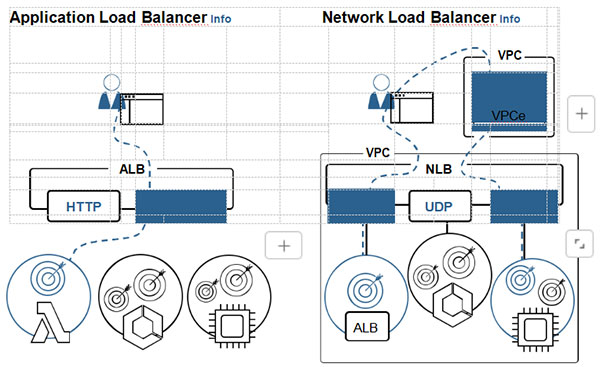
Figure 2-10 Load Balancer Options
Before load-balancing associations and connections can be established at load bal-ancers, network communications using Internet technologies must perform name resolution. The Domain Name System (DNS) Amazon Route 53 service is used to resolve a domain name like www.pearson.com into other domain names (canonically), or into the IPv4 or IPv6 addresses needed to communicate. Rules and policies can be associated with a domain name so that round-robin, priority, failover, weighted, or geolocation will select the results for one end user versus another. Amazon Route 53 also provides inter-region load balancing across AWS regions.
One of the key advantages of the Network, Application, and Route 53 load balanc-ers is that they can monitor the health of the targets they have been configured to distribute queries to. This feedback enables the load balancers to provide actual balancing of the load based on health checks, affinity, stickiness, and security filtering in order to better truly balance the load on your replicas, which allows you to better achieve cost optimization and performance efficiency. Load balancers are also key to application reliability as well.
Failover Architecture
Failover is a critical aspect of load-balancing resources. The ability to have your solutions detect failures and automatically divert to an alternate replica is essential. With automatic failover, you can quickly switchover and reassign requests to the surviving replicas. For database systems, primary–secondary relationships should be designed and deployed.
Failover allows for business continuity in the event of cloud service failure. If there were only two replicas of the application in question and one replica failed, in the failover state you are running without any redundancy. Customers must restore redundancy by either repairing the failed component and bringing it back online or by replacing it. If you deploy triple or greater degrees of redundancy in the first place, recovery from a failure state is not as immediate a concern.
Failover is a general topic that is not just limited to load-balancing technologies. Additional strategies of failover will be addressed in later chapters. It’s important to note that replication, load balancing, and failover are related features that must be orchestrated so that they work in concert with one another. When configured properly, customers can achieve and maintain advantages in security, reliability, and workload performance.